| modele | accuracy | precision | recall | |
|---|---|---|---|---|
| 0 | Multiclasse | 0.881818 | 0.882157 | 0.881818 |
| 1 | OneVsRest | 0.886364 | 0.887026 | 0.886364 |
| 2 | Lasso_CV | 0.886364 | 0.895962 | 0.886364 |
Régressions logistiques
On réalise deux types de régressions : avec et sans pénalisation. La variable d’intérêt, relative au niveau de stress, encode trois modalités différentes. Or une régression logistique classique est utile pour la classification binaire. On choisit donc de comparer dans le cas de la régression sans pénalisation les méthodes multiclasse et One Vs Rest. On réalise enfin une régression Lasso, afin d’avoir un aperçu des variables explicatives les moins importantes (mises à zéro) et d’obtenir un modèle plus parcimonieux. On réalise directement une régression avec validation croisée, afin de sélectionner la valeur de pénalisation fournissant les meilleurs résultats. On obtient pour ces trois modèles des performances équivalentes.
Variables les plus influentes — modèle multiclasse
Nous pouvons également repérer les variables ayant le plus d’impact dans les régressions.
| variable | max_abs_coef | |
|---|---|---|
| 6 | tension_arterielle | 4.933553 |
| 17 | soutien_social | 1.920602 |
| 2 | estime_de_soi | 0.463810 |
| 15 | relation_prof_etudiant | 0.448212 |
| 3 | historique_sante_mentale | 0.443234 |
| 14 | charge_travail | 0.406961 |
| 0 | column00 | 0.394469 |
| 13 | reussite_academique | 0.390265 |
| 12 | besoins_elementaires | 0.342608 |
| 5 | maux_de_tete | 0.298463 |
| variable | 0 | 1 | 2 | |
|---|---|---|---|---|
| 0 | column00 | 0.297605 | -0.614145 | 0.131282 |
| 1 | niveau_anxiete | -0.123173 | 0.204430 | -0.119170 |
| 2 | estime_de_soi | 0.399095 | 0.556294 | -0.671250 |
| 3 | historique_sante_mentale | 0.411234 | -0.764328 | 0.170026 |
| 4 | depression | -0.201115 | -0.156417 | 0.244280 |
| 5 | maux_de_tete | -0.418337 | -0.178068 | 0.463161 |
| 6 | tension_arterielle | 3.551849 | -6.560780 | 7.691669 |
| 7 | qualite_sommeil | 0.276497 | 0.123178 | -0.324324 |
| 8 | problem_respiratoire | -0.134337 | -0.047391 | 0.129895 |
| 9 | niveau_bruit | -0.198406 | -0.118482 | 0.332719 |
| 10 | conditions_vie | -0.029441 | 0.018688 | 0.002337 |
| 11 | securite | 0.303545 | -0.036142 | -0.231550 |
| 12 | besoins_elementaires | 0.527378 | -0.560951 | -0.185329 |
| 13 | reussite_academique | 0.660362 | -0.157042 | -0.489219 |
| 14 | charge_travail | -0.632076 | 0.609399 | 0.159371 |
| 15 | relation_prof_etudiant | 0.247410 | -0.967905 | 0.250030 |
| 16 | perspective_insertion_professionnelle | -0.050372 | 0.124676 | -0.059830 |
| 17 | soutien_social | 1.914309 | -3.908748 | 0.744374 |
| 18 | pression_des_paires | -0.322705 | -0.138926 | 0.310624 |
| 19 | activites_extrascolaires | -0.374013 | 0.156293 | 0.195306 |
| 20 | harcelement | -0.193018 | -0.445681 | 0.332073 |
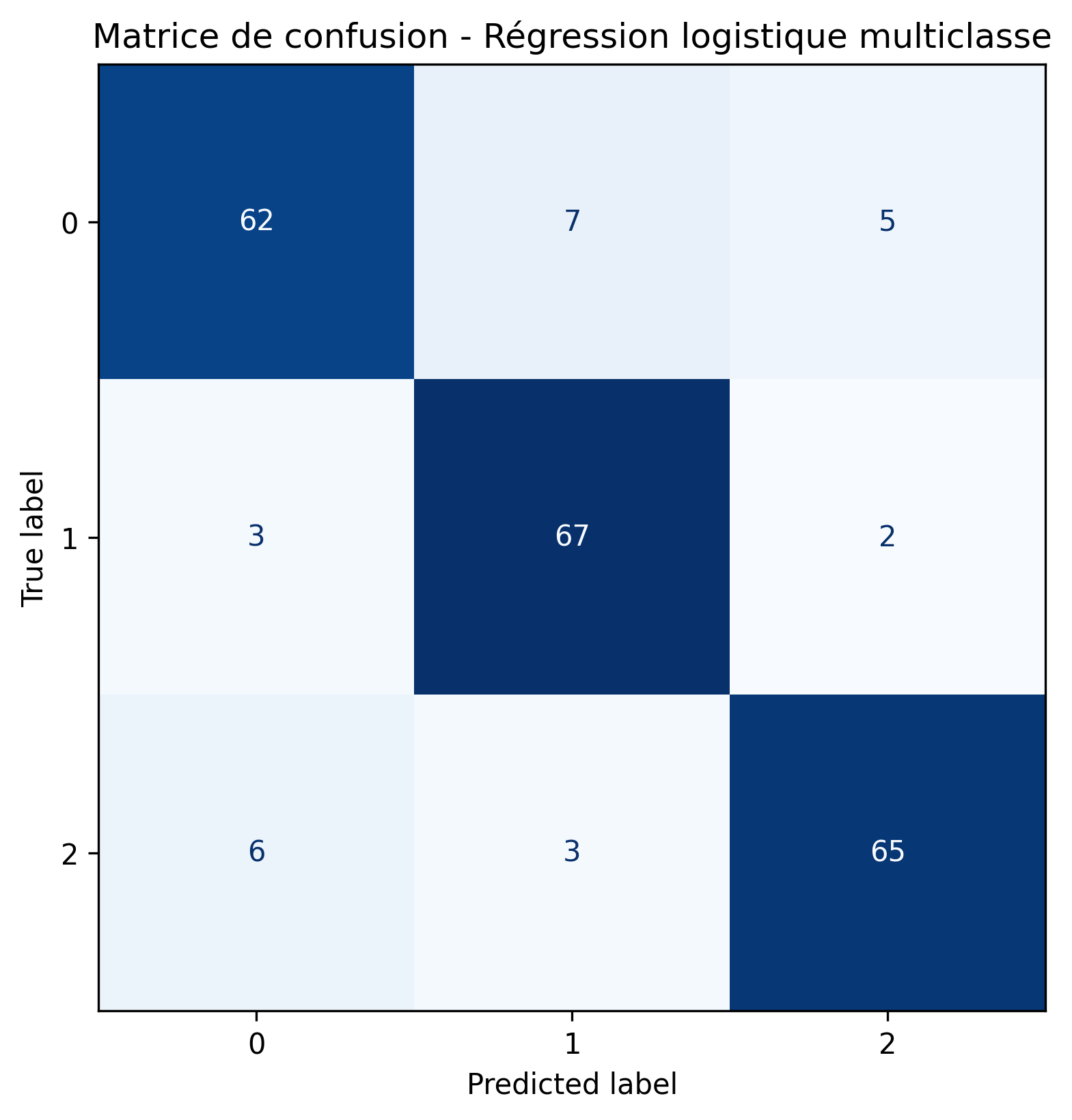
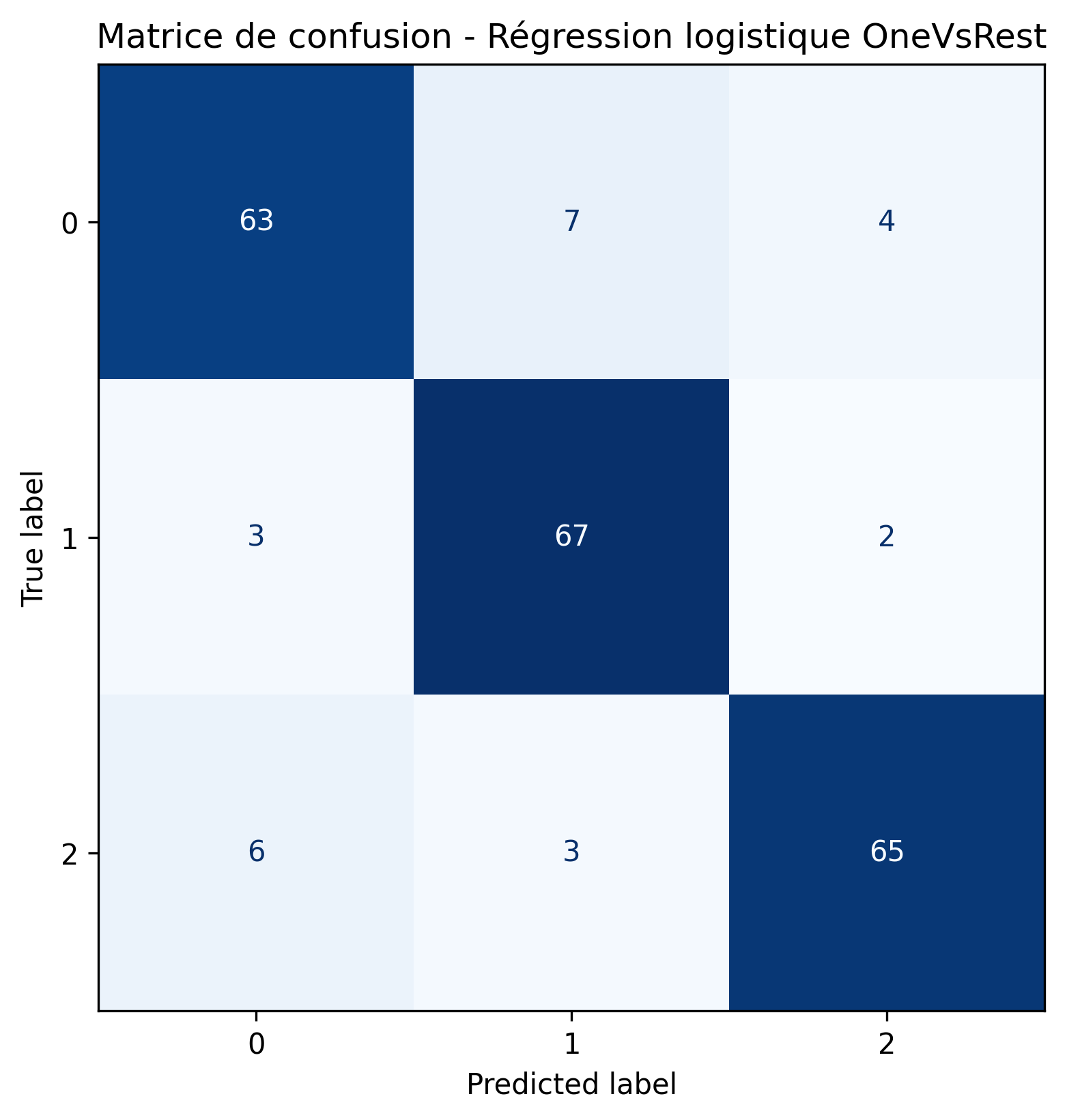
En utilisant ces modèles nous pouvons donc prédire les labels correspondants. Afin de comparer les performances des différents modèles, nous nous intéressons à leur matrice de confusion, afin de visualiser la répartitions des labels, ainsi que les métriques classiques : accuracy, précision et recall.
Meilleur modèle logistique selon l’accuracy : OneVsRest avec une accuracy de 0.886.
Matrices de confusion
Régression logistique multiclasse
Régression logistique One-vs-Rest
| modele | classe | auc | |
|---|---|---|---|
| 0 | Multiclasse | 0 | 0.976860 |
| 1 | Multiclasse | 1 | 0.983296 |
| 2 | Multiclasse | 2 | 0.987134 |
| 3 | Multiclasse | macro | 0.982398 |
| 4 | OneVsRest | 0 | 0.977786 |
| 5 | OneVsRest | 1 | 0.978697 |
| 6 | OneVsRest | 2 | 0.986394 |
| 7 | OneVsRest | macro | 0.980856 |
| 8 | Lasso_CV | 0 | 0.952703 |
| 9 | Lasso_CV | 1 | 0.933089 |
| 10 | Lasso_CV | 2 | 0.979267 |
| 11 | Lasso_CV | macro | 0.955013 |
Comparaison macro-AUC
| modele | classe | auc | |
|---|---|---|---|
| 0 | Multiclasse | macro | 0.982398 |
| 1 | OneVsRest | macro | 0.980856 |
| 2 | Lasso_CV | macro | 0.955013 |
Courbes ROC
Une autre manière de visualiser les performances des trois modèles est de tracer les courbes ROC. Les résultats des trois méthodes sont très satisfaisants et comparables.
Nous observons que les deux méthodes de régressions fournissent des résultats équivalents, les courbes sont superposées, il n’y en n’a pas une très clairement au dessus de l’autre dans chacun des trois cas.
Les résultats des prédictions sont pour les deux méthodes, les meilleurs s’agissant de la classe 1 et les moins bons s’agissant de la classe 0. 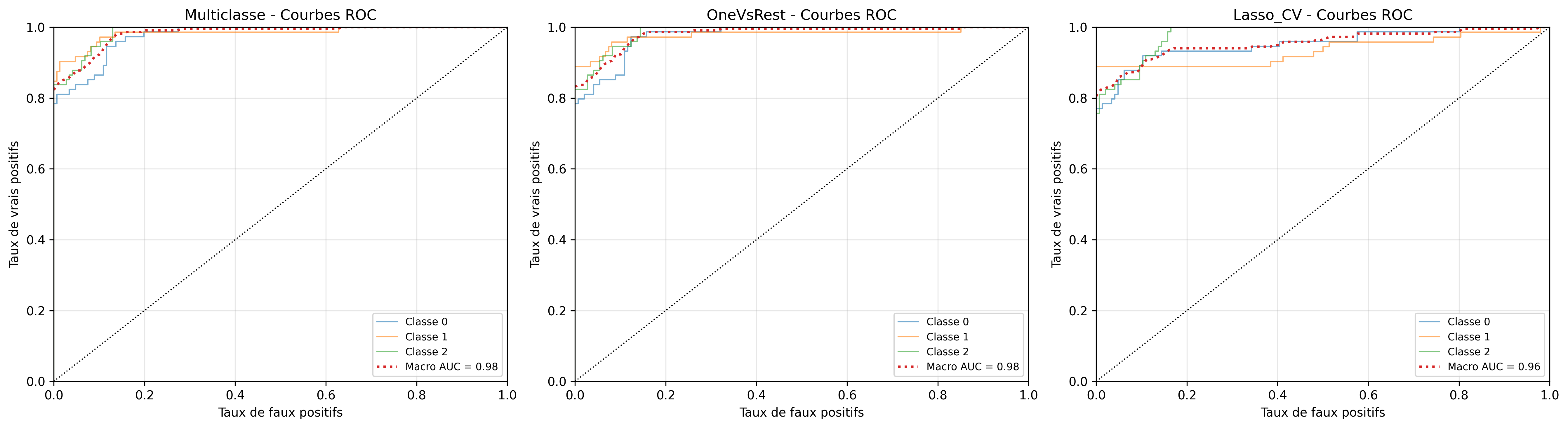
| modele | classe | auc | |
|---|---|---|---|
| 0 | Multiclasse | 0 | 0.976860 |
| 1 | Multiclasse | 1 | 0.983296 |
| 2 | Multiclasse | 2 | 0.987134 |
| 3 | Multiclasse | macro | 0.982398 |
| 4 | OneVsRest | 0 | 0.977786 |
| 5 | OneVsRest | 1 | 0.978697 |
| 6 | OneVsRest | 2 | 0.986394 |
| 7 | OneVsRest | macro | 0.980856 |
| 8 | Lasso_CV | 0 | 0.952703 |
| 9 | Lasso_CV | 1 | 0.933089 |
| 10 | Lasso_CV | 2 | 0.979267 |
| 11 | Lasso_CV | macro | 0.955013 |
Variables les plus influentes — modèle One-vs-Rest
Enfin, ces modèles nous permettent d’évaluer l’influence des variables explicatives sur la variable d’intérêt (ici le niveau de stress) :
| variable | max_abs_coef | |
|---|---|---|
| 6 | tension_arterielle | 7.691669 |
| 17 | soutien_social | 3.908748 |
| 15 | relation_prof_etudiant | 0.967905 |
| 3 | historique_sante_mentale | 0.764328 |
| 2 | estime_de_soi | 0.671250 |
| 13 | reussite_academique | 0.660362 |
| 14 | charge_travail | 0.632076 |
| 0 | column00 | 0.614145 |
| 12 | besoins_elementaires | 0.560951 |
| 5 | maux_de_tete | 0.463161 |
La tension artérielle et le soutien social ressortent comme les variables ayant en valeur absolue le plus grand impact. La régression Lasso nous permet d’exclure certaines variables en mettant leur coefficient à zéro. Nous obtenons :
| Unnamed: 0 | 0 | 1 | 2 | |
|---|---|---|---|---|
| 0 | column00 | 0.000000 | 0.000000 | 0.000000 |
| 1 | niveau_anxiete | -0.178368 | 0.000000 | 0.000000 |
| 2 | estime_de_soi | 0.000000 | 0.000000 | -0.350138 |
| 3 | historique_sante_mentale | 0.000000 | 0.000000 | 0.000000 |
| 4 | depression | 0.000000 | 0.000000 | 0.091729 |
| 5 | maux_de_tete | 0.000000 | 0.000000 | 0.095342 |
| 6 | tension_arterielle | 0.000000 | -1.085586 | 0.604196 |
| 7 | qualite_sommeil | 0.167463 | 0.000000 | 0.000000 |
| 8 | problem_respiratoire | 0.000000 | 0.000000 | 0.000000 |
| 9 | niveau_bruit | 0.000000 | 0.000000 | 0.002253 |
| 10 | conditions_vie | 0.000000 | 0.000000 | 0.000000 |
| 11 | securite | 0.269134 | 0.000000 | 0.000000 |
| 12 | besoins_elementaires | 0.370096 | 0.000000 | 0.000000 |
| 13 | reussite_academique | 0.399375 | 0.000000 | 0.000000 |
| 14 | charge_travail | 0.000000 | 0.000000 | 0.000000 |
| 15 | relation_prof_etudiant | 0.126311 | -0.100958 | 0.000000 |
| 16 | perspective_insertion_professionnelle | 0.000000 | 0.000000 | 0.005598 |
| 17 | soutien_social | 0.000000 | 0.000000 | 0.000000 |
| 18 | pression_des_paires | 0.000000 | 0.000000 | 0.241932 |
| 19 | activites_extrascolaires | 0.000000 | 0.000000 | 0.116408 |
| 20 | harcelement | 0.000000 | 0.000000 | 0.211103 |
Validation croisée
Pour améliorer cette régression, nous réalisons des régressions par validation croisée afin de choisir au mieux la constante de pénalisation \(C\) associée au modèle Lasso.
On donne les intervalles de confiance de l’accuracy score pour chacun des trois modèles de régression. Pour les deux premiers, sans pénalisation, les résultats sont presque égaux, avec une incertitude plus élevée pour la régression multiclasse que OneVsRest. Si l’accuracy score semble plus élevé pour la régression Lasso, en réalité l’intervalle de confiance est également plus grand ie le modèle est moins précis.
| classe | best_c | |
|---|---|---|
| 0 | 0 | 0.01 |
| 1 | 1 | 0.01 |
| 2 | 2 | 0.01 |
Enfin, nous regardons la matrice de confusion de cette nouvelle régression, ainsi que les courbes ROC, classe par classe.
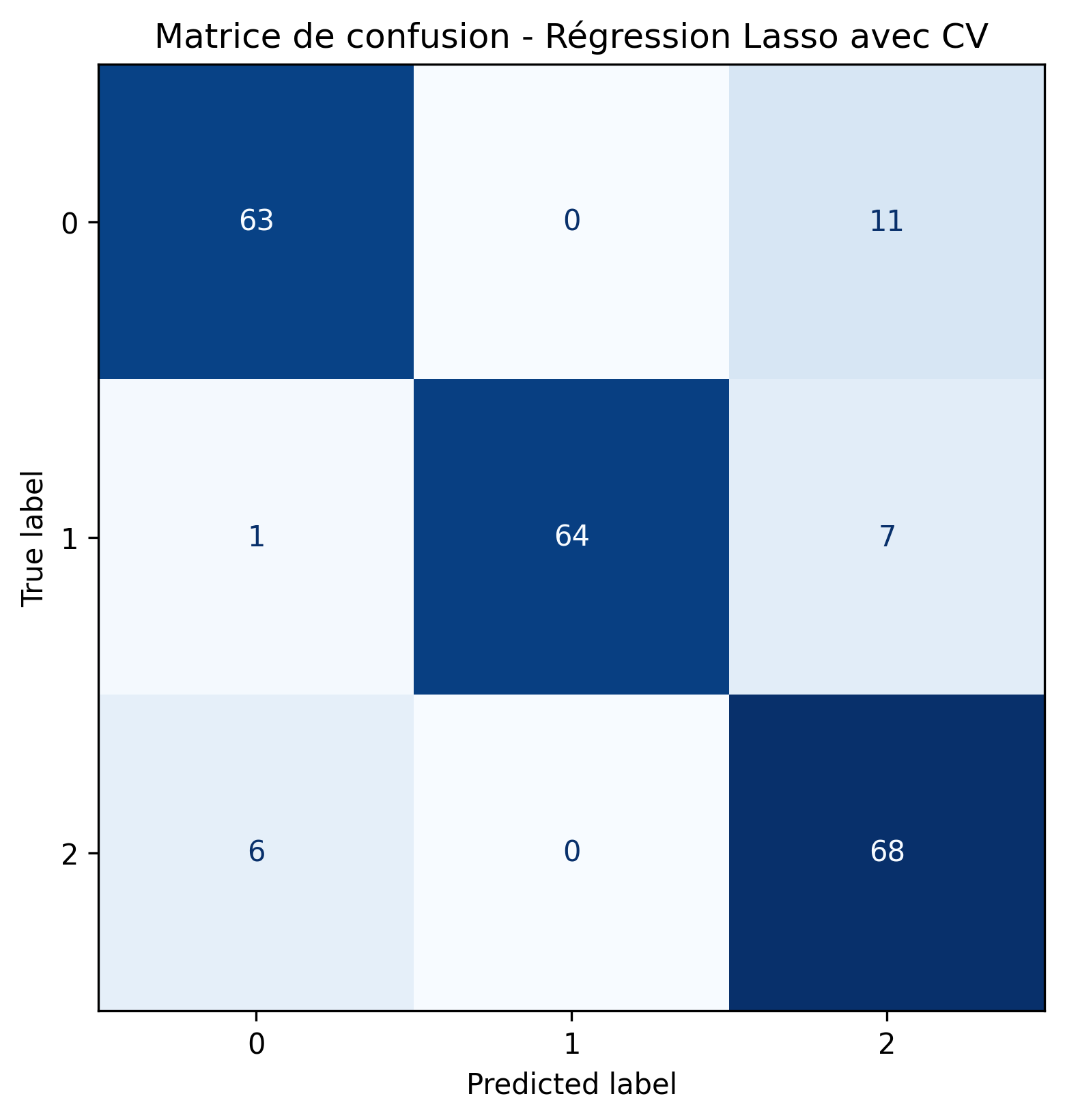
Le modèle Lasso avec constante choisie par validation croisée a un score AUC aussi bon que le modèle OneVsRest dans les trois cas. On dispose donc d’un modèle plus parcimonieux avec des performances équivalentes au modèle incluant toutes les variables explicatives.