| variable | 0 | 1 | 2 | |
|---|---|---|---|---|
| 0 | niveau_anxiete | -0.178368 | 0.000000 | 0.000000 |
| 1 | estime_de_soi | 0.000000 | 0.000000 | -0.350138 |
| 2 | depression | 0.000000 | 0.000000 | 0.091729 |
| 3 | maux_de_tete | 0.000000 | 0.000000 | 0.095342 |
| 4 | tension_arterielle | 0.000000 | -1.085586 | 0.604196 |
| 5 | qualite_sommeil | 0.167463 | 0.000000 | 0.000000 |
| 6 | niveau_bruit | 0.000000 | 0.000000 | 0.002253 |
| 7 | securite | 0.269134 | 0.000000 | 0.000000 |
| 8 | besoins_elementaires | 0.370096 | 0.000000 | 0.000000 |
| 9 | reussite_academique | 0.399375 | 0.000000 | 0.000000 |
| 10 | relation_prof_etudiant | 0.126311 | -0.100958 | 0.000000 |
| 11 | perspective_insertion_professionnelle | 0.000000 | 0.000000 | 0.005598 |
| 12 | pression_des_paires | 0.000000 | 0.000000 | 0.241932 |
| 13 | activites_extrascolaires | 0.000000 | 0.000000 | 0.116408 |
| 14 | harcelement | 0.000000 | 0.000000 | 0.211103 |
Forêt Aléatoire
Nous choisissons ensuite de tester un type de modèle différent : la forêt aléatoire, en espérant améliorer encore les performances.
Pour rappel, avec le modèle de régression Lasso, on avait en regroupant les résultats des trois régressions possibles :
En entrainant une forêt aléatoire, les features les plus importances sont les suivantes.
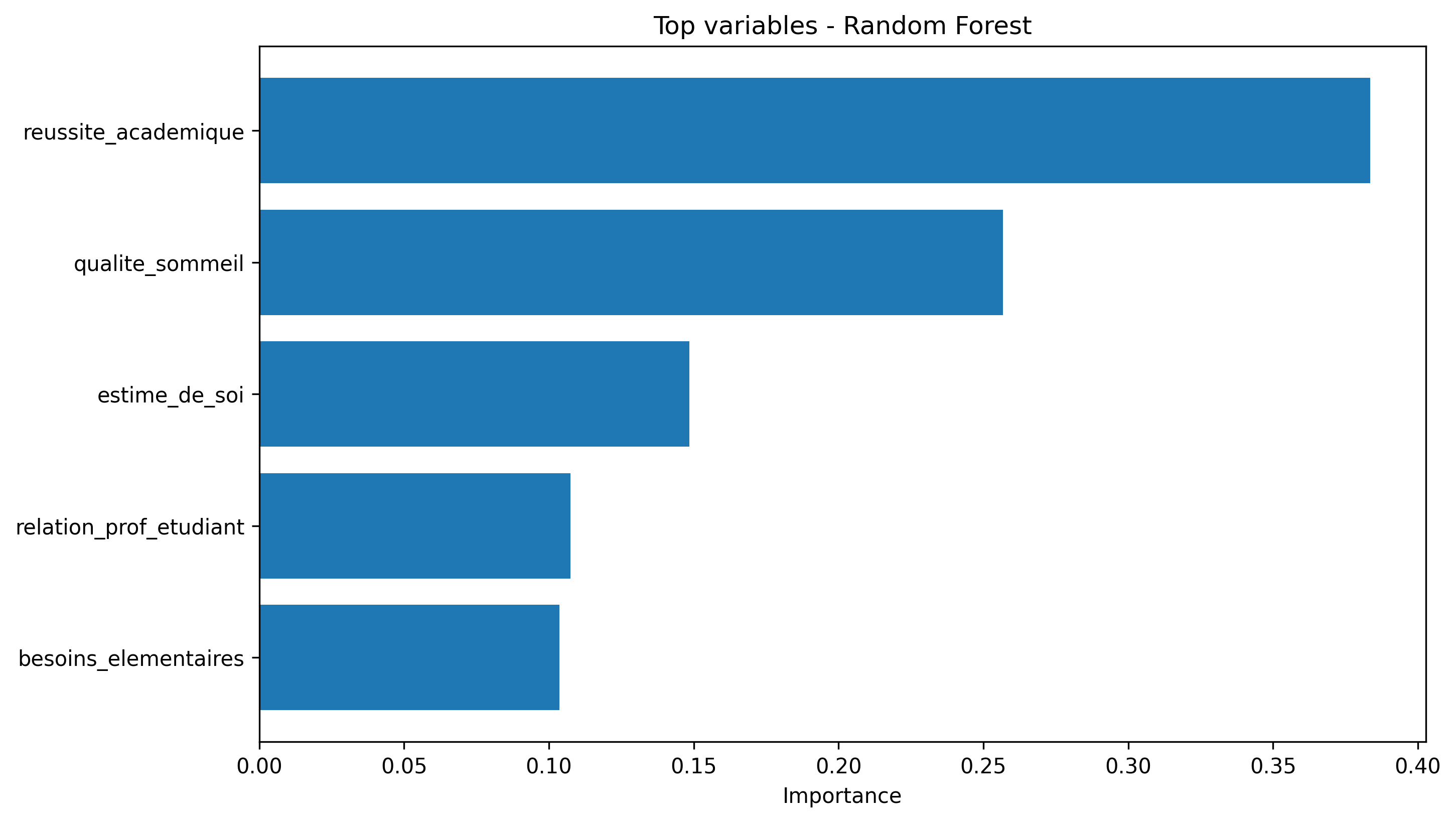
Nous choisissons dans la suite de considérer la même base de données avec un nombre de variables explicatives réduit aux cinq plus importantes données par le résultat ci-dessus. Le but est d’obtenir un modèle parcimonieux et plus facilement interprétable et visualisable qu’en conservant les vingt variables explicatives initiales. Nous entraînons un modèle de forêt aléatoire sur les données, directement avec fine tuning des paramètres (nombre d’arbres, profondeur, nombre minimal de données pour chaque split). Nous évaluons la performance du modèle en calculant la racine de l’erreur quadratique sur les échantillons train (contrôle de l’overfitting) et test. Le résultat obtenu est le suivant :
| model_name | rmse_train | rmse_test | parametres | variables_utilisees | |
|---|---|---|---|---|---|
| 0 | RandomForest | 0.320938 | 0.427311 | {'n_estimators': 200, 'min_samples_split': 10,... | reussite_academique, qualite_sommeil, relation... |
On compare les résultats du modèle de forêt aléatoire au Gradient Boosting, une extension a priori un plus performante de ces modèles. On fine tune ici aussi directement les paramètres afin d’obtenir directement le modèle le plus performant possible. On constate que l’erreur réalisée est légèrement plus importante que celle obtenue avec le modèle de forêts aléatoires.
| model_name | rmse_train | rmse_test | parametres | variables_utilisees | |
|---|---|---|---|---|---|
| 0 | GradientBoosting | 0.303186 | 0.434848 | {'n_estimators': 50, 'max_depth': 3, 'learning... | reussite_academique, qualite_sommeil, relation... |